QSearch 專注於社群網路分析,資料收集是QSearch 的基礎核心,為了分析廣大且即時社群網路資料,系統的選擇與演算法的設計一直是QSearch 技術端專研的方向,讓用戶能即時取得趨勢。
Crawling System 是一個網路機器人系統性地抓取網路上的資訊,包含圖片與文字,這些資訊再被運用在搜尋引擎或數據分析系統。簡單來說,就是寫程式下載網頁內容。隨著網路蓬勃發展,網頁的數量也大量增加,許多機構為了分析網頁的內容,會設計一大型爬蟲( Crawlers ) 去抓取特定網站的內容,由於抓到的內容是給機器看而非直接給人閱讀,對於網站供應商而言是增加流量成本。在講求效率的世界,部分網站供應商調查這些機器人都在抓取哪些資料,轉而提供 API服務,讓網路機器人能有效率抓取重要的資訊,提升抓取效率後,也降低網站供應商負擔。
QSearch 服務整體建置在 Google Cloud Platform 上,爬蟲系統善用 Google App Engine, Google Managed VM 與 Google Compute Engine,每日至少有 100GB 資料必須進入QSearch 系統,結合上述的 Google 服務,能有大頻寬下載能力。
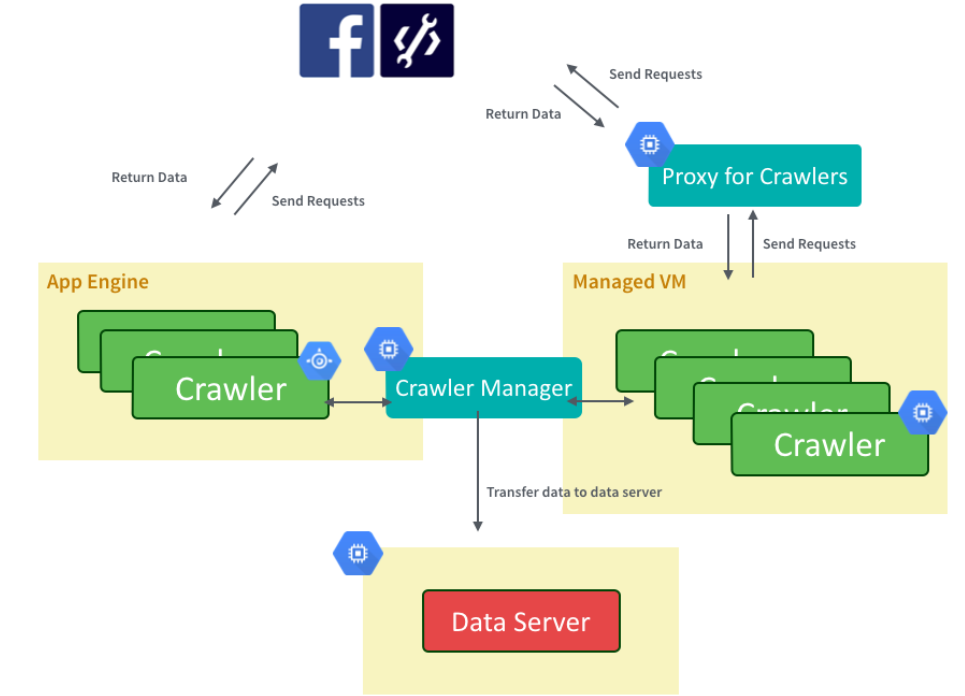
Google App Engine (GAE)是 Platform As a Service,各種基本函式庫都準備好,讓開發者專心寫程式碼,優點是擴展性最好、開發者不太需要煩惱負載平衡等問題(但要稍微煩惱帳單),適合即時、特定熱門粉絲頁抓取,可以幾秒內擴展50~100台機器(Instance)來服務,缺點是 Outbound Traffic 非常貴(USD 0.12/GB),即使是回傳資料給 Google Compute Engine,價格依然相同,Google 內部系統互傳資料沒有比較便宜。
Google Managed VM 是一個更具備開發彈性的計算資源,與最近熱門的 Docker 高度結合。Google 先行準備好 Container 環境,讓開發者直接上傳 Docker Image,並直接運行,優點為好部屬,但是擴展效率比 GAE 慢了一些,同樣要開50~100台機器且穩定至可以處理爬蟲工作的程度,至少約30~60秒。 計算一個 request 不受 GAE 60 秒必須回傳的限制,剛好 Facebook API 亦限制單次回傳資料筆數,假設需要爬某個粉絲頁最近2000篇文章,受限於 Facebook 一次回傳25篇,爬蟲就循序漸進一頁頁爬。由於一頁頁爬很花時間,可能會超過60秒,採用 Google Managed VM 可免除60秒的限制。另外 Google Managed VM 回傳給 Google Computing Engine 的費用為 USD0~USD0.01/GB,成本稍低一些。開發過程中可在本機端先進行環境測試,對於穩定度能更有把握。
Google Compute Engine 在 QSearch 系統主要是被運用為 Crawler Manager,即時偵測回傳量、社群互動量與粉絲頁粉絲數量進行調整 Crawler 排程,並負責安頓好資料做進一步處理。Google Managed VM 與 Google App Engine 皆可透過 API 開關機器,讓資源運用更有效率。
分散式爬蟲設計上需注重 Request Rate,避免失控產生超量的連線,以免瞬間網路供應商判定為攻擊而被阻擋,導致任何資料都無法取得。爬蟲可能再連線過程中會有連線失敗的可能性,因此 Crawler Manager 需要準備一個 Task Queue,當有錯誤發生時自動再次裝載Crawling Task,當錯誤超過一定次數時再請工程師了解。
QSearch 致力於高效能分析系統開發,提供使用者端更穩定的資料分析服務,對我們技術有興趣的朋友們或想要加入技術團隊的朋友們,歡迎與我們聯繫。 NNNN <elliot@qsearch.cc>